


2022 年,我们推出了 Merlin,这是 Shopify 基于 Ray 构建的全新改进机器学习平台。我们构建了一个灵活的平台来支持我们在 Shopify 处理的各种需求、输入、数据类型、依赖性和集成(您可以在我们之前的博客中阅读有关 Merlin 架构的所有信息)。从那时起,我们通过加入更多用例和添加功能来完善端到端机器学习工作流程,从而增强了平台,包括:
- Merlin Online Inference,提供部署和服务机器学习模型以进行实时预测的能力。
- 使用Comet ML进行模型注册和实验跟踪。
- Merlin Pipelines,一个基于 Merlin 的可重现机器学习管道框架。
- Pano Feature Store,一个建立在开源特征商店Feast之上的离线/在线特征商店。
为面向用户的应用程序和服务提供实时预测的能力是 Shopify 的一项重要要求,并且随着越来越多的机器学习模型集成到更接近面向用户的产品中,这一要求将变得越来越重要。但这是一个具有挑战性的要求。由于机器学习被 Shopify 中的许多不同团队使用,每个团队都有自己的用例和要求,因此我们必须确保 Merlin 的在线推理是一个有效的通用解决方案。我们需要构建可被我们所有用例使用并允许低延迟的强大功能,同时以 Shopify 规模提供机器学习模型。
在这篇博文中,我们将介绍如何构建 Merlin 的在线推理功能来部署和服务机器学习模型以进行大规模实时预测。我们将涵盖从服务层到我们利用内部服务生态系统确保在线推理服务可以扩展到 Shopify 功能的服务部署的所有内容,在服务层我们的用户可以只关注他们的特定推理逻辑。
什么是在线推理?
在机器学习工作流程中,一旦模型经过训练、评估和生产化,就可以将其应用于输入数据以返回预测。这称为机器学习推理。有两种主要类型的推理,批量推理和在线推理。
虽然批量推理可以在有限的数据集上定期运行,但在线推理是在输入可用时实时计算预测的能力。通过在线推理,我们生成预测的观察结果可以是无限的,因为我们使用的是随时间生成的数据流。
在许多用例中都可以找到在线推理和实时预测的热门示例。一些例子是推荐系统,其中实时预测可以为用户提供最相关的结果,或欺诈检测,其中需要在欺诈发生时立即检测到的能力。其他受益于在线推理的 Shopify 特定用例是产品分类和收件箱分类。
当为实时预测提供机器学习模型时,与批处理作业相比,延迟变得更加重要,因为机器学习模型的延迟会影响面向用户的服务的性能并影响业务。在考虑机器学习用例的在线推理时,重要的是要考虑:
- 成本
- 用例要求
- 团队成员的技能组合(例如,能够在生产环境中处理运行和维护机器学习服务,而不是在批处理作业中运行它们)。
当我们准备扩展 Merlin 以进行在线推理时,我们首先采访了我们的内部利益相关者,以更好地更详细地了解他们的用例需求。一旦我们有了这些,我们就可以以优化成本和性能的方式设计系统、它的架构和基础设施,并根据机器学习团队用例的服务水平目标,就人员配备和所需支持向他们提供建议.
使用 Merlin 进行在线推理
我们着手为 Merlin Online Inference 提供几个要求:
- 强大而灵活的机器学习模型服务,使我们能够服务和部署 Shopify 使用的不同模型和机器学习库(例如 TensorFlow、PyTorch、XGBoost)。
- 低延迟,以优化推理请求的处理以提供具有最小延迟的响应。
- 在线推理服务的最先进功能,如滚动部署、自动缩放、可观察性、自动模型更新等。
- 与 Merlin 机器学习平台集成,因此用户可以使用不同的 Merlin 功能,例如模型注册和 Pano 在线功能商店。
- 机器学习模型的无缝和简化的服务创建、管理和部署。
考虑到这些要求,我们旨在构建 Merlin Online Inference 以支持部署和服务机器学习模型以进行实时预测。
Merlin 在线推理架构
在我们之前的 Merlin 博文中,我们描述了如何使用 Merlin 训练机器学习模型。借助 Merlin Online Inference,我们可以为我们的数据科学家和机器学习工程师提供工具来部署和服务他们的机器学习模型和用例。
每个需要在线推理的机器学习用例都作为自己的专用服务运行。这些服务与任何其他 Shopify 服务一样部署在 Shopify 的 Kubernetes 集群 ( Google Kubernetes Engine ) 上。每个服务都位于自己的 Kubernetes 命名空间中,并且可以单独配置,例如,根据不同的参数和指标自动缩放。
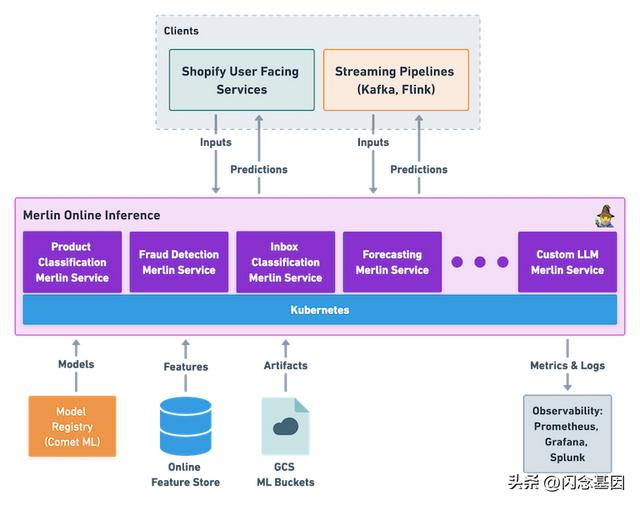
Merlin Online Inference 的高层架构图
每项服务都从我们的模型注册表 Comet ML 以及任何其他所需的工件中加载其专用的机器学习模型。不同的客户端可以调用推理端点来实时生成预测。使用 Merlin 在线推理服务的主要客户端是 Shopify 的核心服务(或任何其他需要实时推理的内部服务),以及Flink 上用于近实时预测的流式管道。我们的特征存储 Pano 可用于在推理期间从 Merlin 在线推理服务或从向服务发送请求的不同客户端访问低延迟特征。
每个服务都有一个监控仪表板,其中包含预定义的指标,例如延迟、每秒请求数、CPU 等。这可用于观察服务的健康状况,并且可以根据服务进一步定制。
每个 Merlin 在线推理服务都有两个主要组件:
- 服务层:使端点能够从模型返回预测的 API。
- 部署:服务将如何部署在 Shopify 的基础设施中。
服务层
Merlin 在线推理服务层是为模型(或多个模型)提供服务的 API。它公开了一个用于处理来自客户端的输入的端点,并返回来自模型的预测。服务层完成以下工作:
- 为该服务启动一个网络服务器
- 作为初始化过程的一部分,将模型和其他工件加载到内存中
- 公开将特征作为输入并返回预测的推理函数的端点
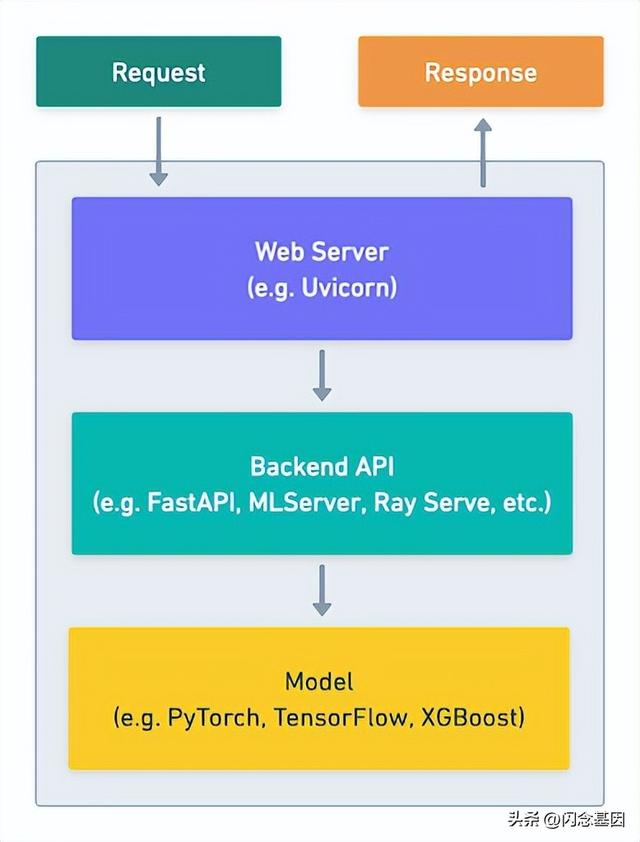
服务层的高级图
服务层是用Python编写的,这使得我们的数据科学家和机器学习工程师更容易实现它。它在每个用例的 Merlin 项目中定义。Merlin 项目是我们 Merlin mono-repo 中的一个文件夹,其中保存了用例的代码、配置和测试。这允许服务层重用机器学习工作流逻辑的不同部分。服务层被添加到 Merlin Docker 镜像中,该镜像由 Podman 从专用的 Dockerfile 创建。然后将其部署在 Merlin Online Inference Kubernetes 集群中。
服务层类型
在分析用户的需求时,我们确定需要支持多种类型的服务层。我们希望确保我们可以从我们的用户那里抽象出很多为每个机器学习用例编写完整 API 的麻烦,同时还启用其他更多自定义服务。
为此,我们目前通过 Merlin Online Inference 支持两种类型的服务库:
- MLServer : Seldon构建的用于机器学习模型的开源推理服务器。MLServer 支持开箱即用的 REST 和 gRPC 接口以及批处理请求的能力。它支持V2 推理协议,该协议标准化了与不同推理服务器的通信协议,从而提高了它们的实用性和可移植性。
- FastAPI:一个快速且高性能的 Web 框架,用于使用 Python 构建 API。
这两个库为我们的用户提供了三种不同的方法来实现他们的在线推理服务层,从使用 MLServer 的无代码或低代码开始,到使用 FastAPI 的完全可定制的 API。下表描述了这些方法之间的区别:
|
服务层类型 |
描述 |
使用什么 |
|
无密码 |
使用 MLServer 的预构建推理服务实现。 只需要在 MLServer json 文件中更改配置。 |
对于这种服务层类型,您有一个模型,您只需将它部署在 Scikit-learn、XGBoost、LightGBM 等端点后面。 |
|
低代码 |
使用 MLServer 的自定义服务实现。需要服务类的最少代码实现。 |
在服务层中包含转换或业务逻辑,或者在 MLServer 中使用不受支持的 ML 库的模型。 |
|
全定制 |
在这种情况下,用户可以获得他们可以完全自定义的 FastAPI 服务层的预定义样板代码。 |
机器学习用例需要公开其他端点或 MLServer 不支持的要求。 |
在 Merlin 中创建服务层
为了抽象掉从头开始编写服务层的大部分复杂性,我们编写了 Merlin CLI,它使用用户的输入来构建自定义服务层。该服务层将从预定义的 cookiecutter 生成,并将提供样板代码供用户构建。
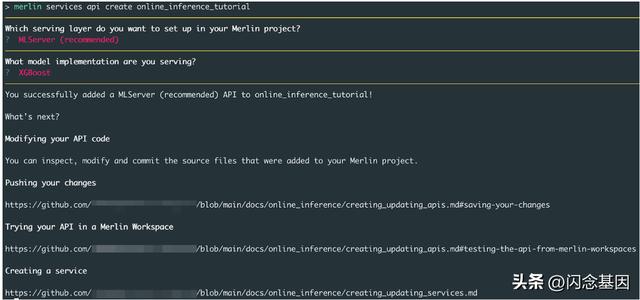
在 Merlin 中创建服务层
在上图中,用户可以选择他们想要在其中实现其服务层的推理库,然后选择他们将用于加载和服务其模型的机器学习库。
使用 MLServer 提供自定义模型的示例
一旦我们为服务层创建了样板代码,我们就可以开始为我们的用例实现特定的逻辑。在下面的示例中,我们提供一个Hugging Face 模型,通过在线推理将英语翻译成法语。
from typing import Any
from mlserver import MLModel
from mlserver.codecs import StringCodec
from mlserver.types import InferenceRequest, InferenceResponse, ResponseOutput
from transformers import pipeline
class CustomInferenceRunner(MLModel):
async def load(self) -> bool:
self._model = pipeline("translation_en_to_fr")
self.ready = True
return self.ready
async def predict(self, payload: InferenceRequest) -> InferenceResponse:
inputs = self._extract_inputs(payload)
text = self._preprocess(inputs)
output = self._model(text)
return InferenceResponse(
id=payload.id,
model_name=self.name,
model_version=self.version,
outputs=[
ResponseOutput(
name="predict",
shape=[len(output)],
datatype="FP32",
data=[output],
)
],
)我们为我们的模型创建一个类,它继承自mlserver.MLModel 并实现以下方法:
- 加载:将模型和任何其他所需的工件加载到内存中。
- 预测:根据方法收到的有效负载从模型生成预测。
此外,对于 MLServer,可以选择仅使用配置文件将模型作为预构建的 HuggingFace 运行时提供:
{
"name": "transformer",
"implementation": "mlserver_huggingface.HuggingFaceRuntime",
"parallel_workers": 0,
"parameters": {
"extra": {
"task": "text-generation",
"pretrained_model": "distilgpt2"
}
}
}以上是一个非常基本的示例,说明如何将低代码和无代码示例与 MLServer 一起使用,而无需从头开始定义整个 API。这使我们的用户可以只关注对他们来说最重要的事情,即加载模型并使用它来生成推理。
使用 Merlin Workspaces 测试服务层
出于测试目的,我们的用户可以利用我们在 Merlin 中已有的工具。他们可以创建 Merlin 工作区,这是可以通过代码、依赖项和所需资源定义的专用环境。这些专用环境还为在其上运行的机器学习任务启用分布式计算和可扩展性。它们的寿命很短,我们的用户可以创建它们,在其中运行服务层,并公开一个用于开发、调试和压力测试的临时端点。这可以在服务层上实现快速迭代,因为它抽象了在每次迭代之间部署完整服务的摩擦。
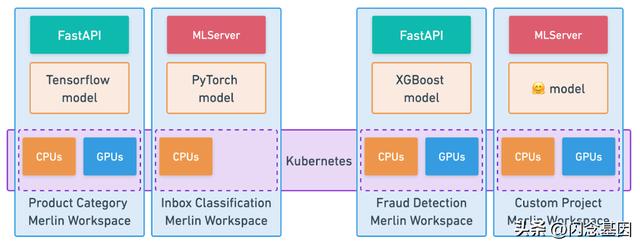
Merlin Workspaces 的高级架构图
在上图中,我们可以看到不同的用例如何在 Merlin 上运行各自的 Merlin 工作区。每个用例都可以定义自己的基础设施资源、机器学习库、Python 包、服务层等,并在隔离和可扩展的环境中运行它们。在这里,我们的用户可以在开发模型和服务层时迭代他们的用例,就像他们在机器学习工作流程的任何其他部分一样。
Merlin 工作区使我们的用户能够访问其 API 的 swagger 页面。这使他们能够测试他们的代码并确保它在将其部署为服务之前可以正常工作。
Merlin 在线推理服务部署
服务层经过测试和验证后,就可以作为服务部署到生产环境中了。部署阶段是将所有 Merlin 组件放在一起以形成已部署服务的阶段。这些组件包括服务层代码、API、模型、工件、库和要求、在 CI/CD 管道中创建的图像容器以及任何其他配置库和包要求,以形成 Merlin 服务。
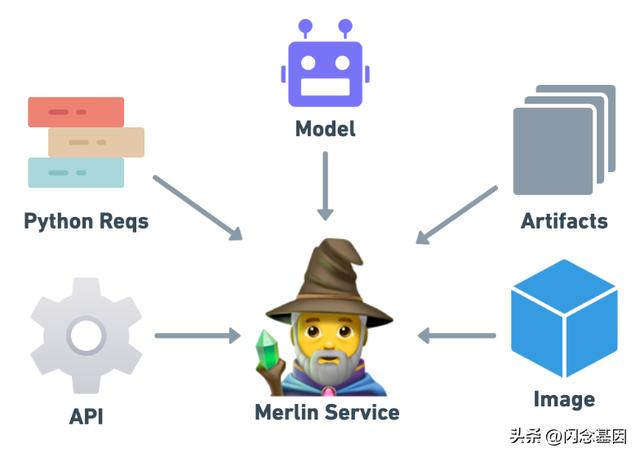
构成 Merlin 服务的组件
创建 Merlin 服务
与服务层创建类似,我们利用相同的 Merlin CLI 在 Shopify 的生态系统中创建 Merlin 服务。生成服务时,我们利用与任何其他 Shopify 服务一样多的 Shopify 服务基础设施来部署 Merlin 服务。这确保 Merlin Services 可以扩展到 Shopify 的功能,并允许他们集成我们现有的工具并从中受益。
创建 Merlin 服务后,它会注册到 Shopify 的服务数据库。Services DB 是一种内部工具,用于跟踪在 Shopify 上运行的所有生产服务。它支持创建新服务并提供全面的视图和工具,以帮助开发团队高质量地维护和运营他们的服务。

Merlin 服务的部署过程
创建 Merlin 服务后,会自动为其生成整个构建和部署工作流程。当用户将新更改合并到他们的存储库时,Shopify 的 Buildkite 管道会自动触发,并在其他操作中为服务构建图像。在工作流的下一步中,然后使用我们的内部 Shipit 管道将该图像部署在 Shopify 的 Kubernetes 集群上。
Merlin 服务配置
每个 Merlin 服务都使用两个配置文件创建,一个用于生产环境,一个用于暂存环境。这些包括服务的资源、参数和相关工件的设置。为每个环境设置不同的配置允许用户为每个环境定义一组不同的资源和参数。这有助于优化服务使用的资源,从而降低基础架构成本。此外,我们的用户可以利用 Merlin Services 的暂存环境来测试新模型版本或配置设置,然后再将它们部署到生产环境中。
以下是 Merlin 服务配置文件的示例,其中包含不同的参数,例如项目名称、元数据、工件路径、CPU、内存、GPU、自动缩放配置等:
merlin_project: classification_model_example
service_name: classification-model-example
serving_layer: mlserver
entrypoint:
- mlserver
- start
- /app/project/mlserver_api
num_replicas: 3
cpu: 2000m
gpu:
count: 1
type: nvidia-tesla-t4
memory: 32Gi
port: 8000
env_vars:
SERVICE_NAME: classification-model-example
PYTORCH_CUDA_ALLOC_CONF: max_split_size_mb:128
auto_scaling:
min_pod_replicas: 3
max_pod_replicas: 10
gpu_utilization: 75
artifacts: []
comet:
environment: production
autodownload: true
models:
- workspace: classification-model-example
version: 0.1.0
model: classification-model-example
dest_path: /comet
stages: []
timeout: 600此示例显示了 classification_model_example 项目的配置文件,该项目使用 MLServer 为其模型提供服务。它使用至少 3 个副本,可以扩展到 10 个副本,每个副本有 2 个 CPU,32 GB 内存和nvidia-tesla-t4 GPU。此外,当服务启动时,它会从我们的模型注册表中加载一个模型。
Merlin 在线推理的下一步是什么
这就是我们部署和服务机器学习模型以使用 Merlin 进行实时预测的路径。总而言之,我们的用户首先创建一个 Merlin 项目,其中包含他们的机器学习用例所需的一切。系统会自动为他们的项目构建一个图像,然后将其用于训练管道,从而生成一个经过训练的模型,并将其保存到我们的模型注册表中。如果用例需要在线推理,可以使用 Merlin 创建服务层和专用的 Merlin 服务。将服务部署到生产环境后,Merlin 用户可以继续迭代他们的模型并在新版本可用时进行部署。
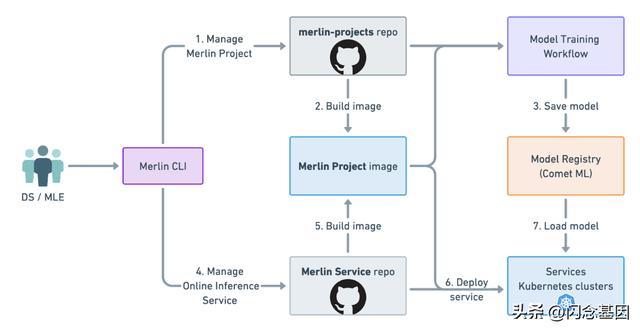
用户旅程的高级概述
当我们将新的在线推理用例引入 Merlin 时,我们计划解决其他领域,以实现:
- 集成模型/推理图: 虽然我们有能力部署和服务机器学习模型,但我们知道在某些情况下我们需要在推理过程中组合多个模型。我们正在研究利用一些开源工具来帮助我们通过 Ray Serve、 Seldon Core 或 BentoML实现这一目标。
- 在线推理监控: 利用我们目前的能力,可以创建工作流、指标和仪表板来检测不同的漂移。然而,目前这一步完全是手动的,需要我们的用户付出很多努力。我们希望启用一个基于平台的监控解决方案,该解决方案将与 Merlin 的其余部分无缝集成。
- 持续训练: 随着用于预测的输入和数据量的增加,我们的一些用例将需要更频繁地开始训练他们的模型,并且需要一个自动化且更简单的部署过程。我们正在研究使我们的在线推理模型的更多服务管理流程和生命周期自动化。
虽然在线推理仍然是 Merlin 的新部分,但它已经为我们的用户和数据科学团队提供了我们在设计它时所考虑的低延迟、可扩展性和快速迭代。我们很高兴能够继续构建平台并引入新的用例,这样我们就可以继续释放新的可能性,让商家始终处于创新的前沿。借助 Merlin,我们帮助启用由 Shopify 提供支持的数百万家企业。
作者:
Isaac Vidas 是 ML 平台团队的技术主管,专注于设计和构建 Shopify 的机器学习平台 Merlin。在LinkedIn上与 Isaac 联系。
出处:https://shopify.engineering/shopifys-machine-learning-platform-real-time-predictions
创业项目群,学习操作 18个小项目,添加 微信:luao319 备注:小项目!
如若转载,请注明出处:https://www.fqkj168.cn/2820.html
相关推荐
-
老bbb老bbb肥女视频在线观看,老bbnbbnbbnbbn
2012年10月22日下午三点,甘肃省庆阳市合水县某村,有几个小孩在村外小河沟旁边玩,一个小孩忽然看到小河沟下面躺着一个人,吓得大叫一声,另外几个小孩也跑过来观看,几个人看到后一起…
-
hentaivideo,e站
捷克作为中欧地区的一个国家,素来以其广阔的历史和文化底蕴而著名。但是最近几年,捷克的色情产业也逐渐崛起并成为了该国的一个特色行业。根据有关数据显示,每10万人口中就有7人曾经参与过…
-
成本低利润高的小吃,成本低利润高的小吃摆摊
大家好,我是小青。湖南长沙炒毛豆是一道口感十分香脆的小吃,深受广大食客的喜爱。其制作简单,原材料易得,但要想做出香鲜美味的炒毛豆,需要掌握一些技巧。在此,我将为你详细介绍长沙炒毛豆…
-
什么样的人不能做近视手术,什么样的人不能做近视手术呢
近视手术作为一种常见的治疗近视的方式,在改善视力方面发挥了巨大的作用。然而,并非所有人都适合进行近视手术。那么,什么样的人不能做近视手术呢?接下来我们来了解下。 首先,那些年龄太小…
-
alevel国际课程中心,哈尔滨工程大学alevel国际课程中心
最近有位家长向小助手咨询,孩子目前在IB一梯队上学,正考虑转校去学习A-Level,他们想知道如何才能顺利地转换课程,以及这个决定对孩子的影响如何。 01 孩子学到一半换学校? 走…
-
挣点小钱的副业,挣点小钱的副业知乎
在这个经济不景气的时代,很多人都在寻找一些额外的收入来源。而副业就成为了很多人的选择。但是,如何挣到一些小钱呢?知乎上有哪些好的建议呢? 首先,我们需要明确一点,挣点小钱的副业并不…
-
连裤袜肉丝美脚在线影院,连裤袜肉丝美脚在线影院亚洲一区
美女与豹人。第1集。 女人第一次穿黑丝接客,突然她看见床底下出现一条黑色尾巴在脚边动来动去。就在此时,这一幕让女人瞬间震惊。女人大声尖叫使劲挣扎,终于冲出房间并顺着楼梯往下爬不断逃…
-
动静脉内瘘成形术,
动静脉内瘘成形术的意义和技术发展 动静脉内瘘成形术是一种重要的介入治疗手段,被广泛应用于肾透析、血液净化等领域。本文将探讨动静脉内瘘成形术的意义以及技术发展。 1. 动静脉内瘘成形…
-
渝北区小吃餐饮招商加盟网站,渝北区小吃餐饮招商加盟网站有哪些
【导言】 重庆作为中国的火锅之都和美食之都,拥有丰富多样的美食文化。 近期,对重庆市的38个区县的美食进行了一次全面评比。本文将带您逐一了解各区县的美食排名情况,看看哪些区县的美食…
-
中山成考教育网站,中山成考教育网站官网
成考怎么查教学点/画授站?靠谱机构防骗妙招!魏老师谈学历。报成考的同学,我劝你一定要去做一下这个操作,决定了你的血汗钱会不会打水漂。那就是查一查你报读的学校,是不是学校的官方教学点…