


什么是Transformer 模型?
Transformer 模型是一种神经网络架构,可以自动将一种类型的输入转换为另一种类型的输出。这个术语是在 2017 年的一篇谷歌论文中创造的,该论文找到了一种训练神经网络的方法,可以更准确地将英语翻译成法语,并且训练时间是其他神经网络的四分之一。
事实证明,该技术比作者意识到的更具普遍性,而且转换器已用于生成文本、图像和机器人指令。它还可以对不同数据模式之间的关系进行建模,称为多模式 AI,用于将自然语言指令转换为图像或机器人指令。
Transformer 在所有大型语言模型 (LLM) 应用程序中都至关重要,包括ChatGPT、Google Search、Dall-E 和 Microsoft Copilot。
几乎所有使用自然语言处理的应用程序现在都在底层使用转换器,因为它们比以前的方法性能更好。研究人员还发现,Transformer 模型可以学习处理化学结构、预测蛋白质折叠和大规模分析医学数据。
Transformer 的一个重要方面是它们如何利用称为注意力的 AI 概念来强调相关词的权重,这些词可以帮助绘制描述其他类型数据(例如图像的一部分)的给定词或标记的上下文或蛋白质结构——或语音音素。
自 1990 年代以来,注意力的概念就作为一种处理技术出现了。然而,在 2017 年,一个谷歌工作团队建议他们可以使用注意力来直接编码单词的含义和给定语言的结构。这是革命性的,因为它取代了以前需要使用专用神经网络的额外编码步骤。它还开辟了一种对任何类型的信息进行虚拟建模的方法,为过去几年出现的非凡突破铺平了道路。
Transformer 模型可以做什么?
Transformer 在许多应用中逐渐取代了以前最流行的深度学习神经网络架构类型,包括递归神经网络 ( RNN ) 和卷积神经网络(CNN)。RNN 非常适合处理语音、句子和代码等数据流。但他们一次只能处理较短的字符串。较新的技术,例如长短期记忆,是 RNN 方法,可以支持更长的字符串,但仍然有限且速度慢。相比之下,Transformer 可以处理更长的序列,并且可以并行处理每个单词或标记,这使它们能够更有效地扩展。
CNN 是处理数据的理想选择,例如并行分析照片的多个区域以确定线条、形状和纹理等特征的相似性。这些网络针对比较附近区域进行了优化。相比之下,Transformer 模型(例如 2021 年推出的 Vision Transformer)似乎在比较可能彼此远离的区域方面做得更好。Transformers 还可以更好地处理未标记的数据。
变形金刚可以通过分析大量未标记数据来学习有效地表示文本的含义。这让研究人员可以扩展转换器以支持数千亿甚至数万亿个功能。在实践中,使用未标记数据创建的预训练模型仅作为使用标记数据进一步优化特定任务的起点。然而,这是可以接受的,因为第二步需要较少的专业知识和处理能力。
Transformer 模型架构
Transformer 架构由协同工作的编码器和解码器组成。注意力机制让转换器根据其他单词或标记的估计重要性对单词的含义进行编码。这使转换器能够并行处理所有单词或标记以获得更快的性能,从而帮助推动越来越大的 LLM 的增长。
由于注意力机制,编码器块将每个单词或标记转换为由其他单词进一步加权的向量。例如,在下面的两个句子中,由于单词filled变为emptied ,它的含义将被不同地加权:
- 他把水罐倒进杯子里,装满了。
- 他把水罐倒进杯子里,倒空了。
注意机制会将其与第一句话中装满的杯子和第二句话中倒空的水罐联系起来。
解码器基本上反转了目标域中的过程。最初的用例是将英语翻译成法语,但同样的机制可以将简短的英语问题和说明翻译成更长的答案。相反,它可以将较长的文章翻译成更简洁的摘要。
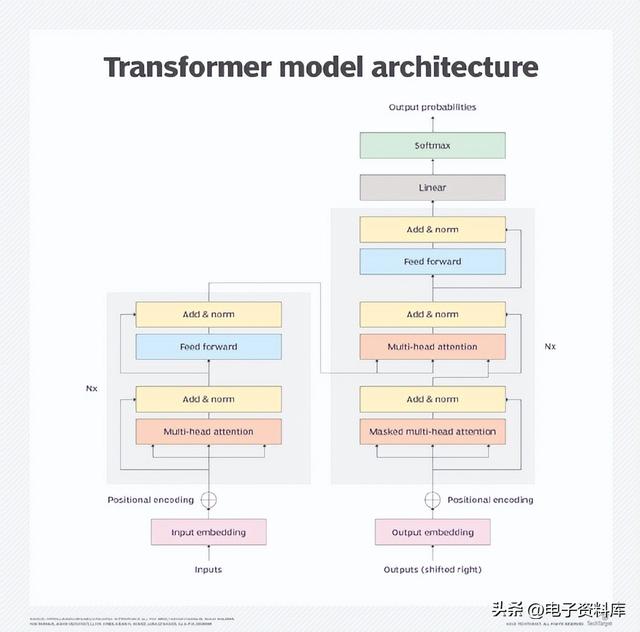
Transformer 模型架构。
Transformer模型训练
训练Transformer 模型涉及两个关键阶段。在第一阶段,转换器处理大量未标记的数据以了解语言的结构或现象,例如蛋白质折叠,以及附近的元素似乎如何相互影响。这是过程中成本高且耗能大的方面。训练一些最大的模型可能需要数百万美元。
训练模型后,针对特定任务对其进行微调会很有帮助。一家技术公司可能希望调整聊天机器人,以根据用户的知识以不同的详细程度响应不同的客户服务和技术支持查询。律师事务所可能会调整分析合同的模型。开发团队可能会根据自己的大量代码库和独特的编码约定调整模型。
微调过程需要的专业知识和处理能力要少得多。Transformer 的支持者认为,用于训练更大的通用模型的大笔费用可以得到回报,因为它可以节省为许多不同用例定制模型的时间和金钱。
模型中的特征数量有时被用作其性能的代理,而不是更显着的指标。然而,特征的数量——或模型的大小——并不直接与性能或实用程序进行校准。例如,谷歌最近尝试使用专家混合技术更有效地训练法学硕士,事实证明这种技术的效率是其他模型的七倍左右。尽管其中一些模型的参数超过一万亿,但它们的精度不如参数少数百倍的模型。
然而,Meta 最近报告说,其具有 130 亿个参数的大型语言模型元 AI (Llama) 在主要基准测试中的表现优于具有 1750 亿个参数的生成式预训练转换器 (GPT) 模型。Llama的 650 亿参数变体与具有超过 5000 亿参数的模型的性能相匹配。
Transformer 模型应用
转换器几乎可以应用于任何处理给定输入类型以生成输出的任务。示例包括以下用例:
- 从一种语言翻译成另一种语言。
- 编写更具吸引力和实用性的聊天机器人。
- 总结长文档。
- 从简短提示生成长文档。
- 根据特定提示生成药物化学结构。
- 从文本提示生成图像。
- 为图像创建标题。
- 根据简短描述创建机器人流程自动化 ( RPA ) 脚本。
- 根据现有代码提供代码补全建议。
Transformer 模型实现
Transformer 的实施在规模、对新用例或不同领域(例如医学、科学或商业应用程序)的支持方面正在改进。以下是一些最有前途的Transformer 模型实现:
- Google 的 Bidirectional Encoder Representations from Transformers 是首批基于 Transformers 的 LLM 之一。
- OpenAI 的 GPT 紧随其后,经历了数次迭代,包括 GPT-2、GPT-3、GPT-3.5、GPT-4 和 ChatGPT。
- Meta 的 Llama 与尺寸是其 10 倍的模型实现了相当的性能。
- Google 的 Pathways 语言模型概括并执行跨多个领域的任务,包括文本、图像和机器人控制。
- Open AI 的 Dall-E根据简短的文本描述创建图像。
- 佛罗里达大学和 Nvidia 的 GatorTron 分析来自医疗记录的非结构化数据。
- DeepMind 的 Alphafold 2 描述了蛋白质如何折叠。
- AstraZeneca 和 Nvidia 的 MegaMolBART 根据化学结构数据生成新的候选药物。
创业项目群,学习操作 18个小项目,添加 微信:luao319 备注:小项目!
如若转载,请注明出处:https://www.fqkj168.cn/6843.html
相关推荐
-
红包封面分销,红包封面分销平台
在当今社交媒体和电商兴起的时代,红包已经成为人们社交互动和传播情感的重要方式。无疑,红包封面分销平台正处于蓬勃发展之中,成为了一个充满商机的领域。 ### 什么是红包封面分销? 首…
-
正规的网络创业项目哪里有,网络创业项目一般在哪里找
6月8日上午,位于深圳八卦岭片区的青苹果直播电商产业园文博会分会场进入合作项目的丰收季,国家对外文化贸易基地(深圳)直播基地、老龄智慧科技直播联盟、新疆贵州乡村振兴直播间、智能机器…
-
抖音看久了一卡一卡的,抖音看久了一卡一卡的网络没有问题
最近一段时间拍了很多美景视频,编辑发布到头条后,有时一直显示在缓冲,播放不了,有时打开断断续续的,老是卡顿。导致的后果是:要么展现量很低,要么阅读量寥寥无几,这让我非常苦恼。 图片…
-
cogito人工智能,go人工智能
新华社德国汉诺威4月20日电 (国际观察)人工智能赋能工业制造,一切刚刚开始 新华社记者郭爽 李超 杜哲宇 “工业4.0定义了过去十年的发展,生产线上各个组件开始被连接起来……如今…
-
淘宝虚拟资源货源,淘宝虚拟资源货源怎么找
大家好,我是大牛,久等了,今天正式开始讲解无货源的做法。 ·先讲最基础的无货源是什么?首先了解清楚这个问题,所谓无货源,简单来说假如某多多上面有个品看中了觉得价格挺实惠,就把它加个…
-
华夏基石,华夏基石咨询公司
华夏基石咨询公司是一家专业的企业管理咨询公司,成立于2005年,总部位于北京市。公司致力于为客户提供全方位的咨询服务,包括战略规划、组织架构设计、人力资源管理、财务管理、市场营销等…
-
安全事故案例分析,安全事故案例分析原因及措施
市安委会办公室关于2022年十起生产安全事故典型案例的通报 各区安委会、市安委会有关成员单位: 刚刚过去的2022年是极为重要、极不平凡的一年,全市上下深入学习贯彻习近平总书记关于…
-
网络呼叫软件打电话,网络呼叫软件打电话是干嘛的?
随着科技的进步和互联网的普及,网络呼叫软件已成为人们日常通话的重要方式。无论是个人使用还是商务通讯,网络呼叫软件的出现改变了我们传统的通话方式,为我们带来了许多便利和创新。 那么,…
-
openai_chatgpt,openai_chatgpt
欧盟中央数据监管机构欧洲数据保护委员会(EDPB)13日表示,正在成立一个特别工作组,帮助欧盟各国应对广受欢迎的人工智能聊天机器人ChatGPT,促进欧盟各国之间的合作,并就数据保…
-
小学生眼保健操的来历,小学生眼保健操意义
九江新闻网讯(潘慧萍)为培养学生良好的用眼卫生习惯,降低学生近视率,进一步提高学生做眼保健操的质量,促进学生养成保护视力的良好行为习惯,5月16日下午,浔阳小学举行了眼保健操比赛。…