
一个朋友提醒我,从现在起,必须高度关注人工智能,这两天刚好有点时间,学习了一下,在此给大家分享一下。
人工智能最底层的算法叫神经网络算法,其想法来自于仿生学,神经网络模型是模仿人脑神经元而来。人大脑中约有860亿个神经元,这些神经元之间相互连接并传递信息,从而完成人们日常生活中的各种复杂信息处理。神经元主要由胞体、树突和轴突组成,其中树突将接收信号传入神经元,胞体处理传入信号,再由轴突将信号传出,如下图所示。人脑的神经元分为两种状态,即静息态(非激活状态)和发送电位信号状态(激活状态),这是由于神经元的胞体存在一种非常重要的机制——阈值,即只有输入的电信号达到阈值时,胞体才会激活,并继续向前传出电信号。
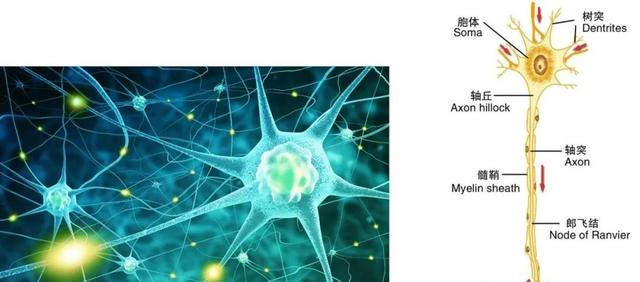

图1:神经元
1943年,由神经科学家麦卡洛克(W.S.McCilloch) 和数学家皮兹(W.Pitts)在《数学生物物理学公告》上发表论文《神经活动中内在思想的逻辑演算》(A Logical Calculus of the Ideas Immanent in Nervous Activity)。建立了神经网络和数学模型,称为MCP模型。MCP当时是希望能够用计算机来模拟人的神经元反应的过程,该模型将神经元简化为了三个过程:输入信号线性加权,求和,非线性激活(阈值法)。如下图所示:
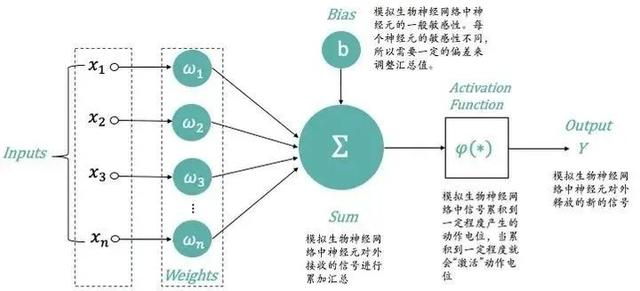
图2:MCP模型
以我的理解,所谓的训练,就是不断给出X训练矩阵,得出一个Y矩阵,将Y矩阵和真值Y*进行对比,不断修正ω和b,使得Y与真值Y*足够接近。训练好的模型,就是最终得到一个恰到好处的ω和b,使得这个模型对于其他未经训练的X,能够得到想要的Y。当然这个早期模型的缺点明显,仅仅能处理线性问题。
后来又有科学家提出了深度学习的模型,就是给输入和输出中间加了好几层隐藏层,增加了好几种函数和更多的参数进去,其实就相当于增加了脑回路。但是增加了训练的复杂度和计算量。这种模型称作MP模型。
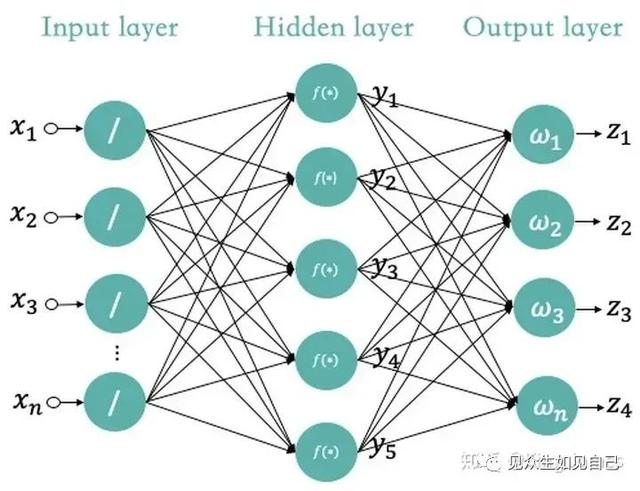
图3:MP模型
所以一直到2006年,号称AI之父的Geoffrey Hinton老爷子提出了一种新的解决方案:无监督预训练对权值进行初始化+有监督训练微调。在我理解就是对训练过程进行一些干预,缩短训练的步伐,提高训练的成功率。
关于Hinton老爷子的传奇经历,有必要详细介绍一下:
Geoffrey Everest Hinton出生在英国南部的温布尔登,在布里斯托尔长大,
母亲(Margaret Clark)是一位数学老师,父亲(Howard Everest Hinton)是一位专注甲壳虫研究的昆虫学家。
Hinton的父亲是一个对体力和智力都严苛要求、让人心生敬畏的父亲,Hinton回忆说,“他喜欢那些思维清晰的人。如果你说了哪怕一点废话,他就会称其为垃圾。他不是那种多愁善感的思想者,他也不会虐待人,但他确实极其强硬。”
Hinton的曾祖父(Charles Howard Hinton)是一名数学家和科幻作家。
中学时,Hinton在克里夫顿学院结识了一位朋友了解到了全息图,其中讲到了人脑如何存储记忆,这是Hinton的AI之路的开始。
18岁的Hinton进入剑桥大学国王学院攻读物理和化学,但只读了一个月就退学了。一年之后,他又重新申请了国王学院的建筑学,结果又退学了,这次他只坚持了一天。之后又转向了物理和生理学,后来又转到了哲学,花1年修完了2年的课程,结果和自己的导师吵了起来。最后的最后,他转向了心理学,并在1970年获得实验心理学学士学位。毕竟,优秀的人才都要经历几次退学。
毕业后Hinton成了一名木匠,一边做书架、木门,一边思考大脑工作原理。
短暂的体力劳动后又回归了学术界。1972年,Hinton进入爱丁堡大学,开始读人工智能博士,主攻神经网络。
一次,Hinton参加了一个类似EST-y的研讨班。活动最后一天,每个人都要宣布各自生命中最最想要的东西。当大家在窃窃私语说想要被爱时,Hinton的宣言令自己和大家都大吃一惊。“我真正想要的是一个博士!”,他怒吼到,点燃了一个7岁时就藏匿在内心的想法。
为了找到一个支持他研究神经网络的栖身之处,也避免研究被用于军事项目,Hinton来到了加拿大高级研究所(CIFAR),就是CIFAR10/CIFAR100数据集中的那个CIFAR,最后落脚在加拿大的多伦多大学。
如今因为Hinton,加拿大现已成为AI研究的重要力量之一,吸引了多家人工智慧巨头将研究中心开到了多伦多。
来到加拿大后,Hinton慢慢的有了一小撮深度学习的跟随者,包括OPENAI的联合创始人兼董事伊利亚?苏奇凯弗(Ilya sutskever)等。
80年代早期计算机没有能力处理神经网络所需的大量数据,所以Hinton等人的成功是有限的,当时AI的主流方向不是模仿大脑。AI研究的工作岗位和资金稀缺使得这10名左右的团队在“AI寒冬”的黑暗中等待着黎明。
21世纪初期,Hinton被一些学术机构,AI与计算机科学领域的圈子拒之门外。参加学术会议时,Hinton常坐在房间的最角落里,在大牛云集的会议上完全被忽视。
直到这个世界开始慢慢追上他的脚步。
进入21世纪后计算机硬件的能力发展迅速,数据以惊人的速度开始积累,神经网络的训练开始变得可行。
2006年Hinton在Science上发表文章揭开了深度学习的序幕。2009年Hinton的2位学生使用神经网络赢下了一个语音识别比赛。2012年另外两个学生轻松赢下了当年的ImageNet ILSVRC挑战赛,提出著名的AlexNet。
Hinton说:“我们不再是疯子边缘,我们现在是疯狂的核心”。
Hinton的脚步从未停歇,2017年发表了Capsule Networks(胶囊网络),带来了深度学习的新研究方向。
早在2012年百度就邀请Hinton加入,当时给开价1200万美金。但是Hinton的学生提议,不如他们成立一个公司,然后找其他公司收购,收购者既可以是百度,也可以是其他公司。
Hinton最终采纳了他们的意见,和他的两位学生一起创建了一家只有他们三名成员的公司。公司的名字,就叫DNNresearch。
在咨询过一位律师之后,Hinton最终决定为这家公司举行一次竞拍,以让这家只有三名员工、没有产品也没有历史的初创公司的价值最大化。
参加这次竞拍的,一共有四家公司:谷歌、微软、DeepMind,还有百度。
竞拍最终就在Hinton所住的赫拉斯酒店的731房间里进行。
竞拍的方式是通过Gmail:四家公司的高管用邮件远程进行出价,每次竞价后,四家公司有一个小时的时间将购买价格提高至少100万美元。一个小时结束后,如果没有人提出新的报价,拍卖即宣告结束。
微软对这种方式提出了异议——他们认为谷歌可能会偷偷读取Gmail中的邮件。
但商量过后,Hinton最终还是决定采用这种方式,因为他们“相当确信谷歌不会读取Gmail“。
此时此刻,不管是百度,还是其他公司,似乎都已经预感到了这场拍卖的最终结局。
但百度没有放弃。
拍卖开始不久,DeepMind首先退出——他们用公司的股票期权进行出价,而非现金。显而易见,作为一家初创公司,他们缺少和几家巨头展开竞争的资本。
竞价达到2200万美元时,微软退出。
此时这场拍卖的竞争者,只剩下百度和谷歌两家。
尽管身处不利的位置,百度依然决定放手一搏。
2500万美元,3000万美元,3500万美元……他们开始大幅提升竞拍的价格,希望以此打动Hinton的团队。
看着竞价的数字在眼前的电脑屏幕上飞升,Hinton和他的两个学生都产生了一丝不真实的感觉。
“简直就像是我们走进了一场电影里。”
竞价一直攀升到4400万美元时,有了我们开头的那一幕。
百度最终还是没能如愿以偿。
在第二天的竞标正式开始之前,百度收到了一封来自Hinton的邮件,通知他们,拍卖结束了。
竞拍的价格停留在了4400万美元(约合2.88亿元)。Hinton在邮件中说,公司发送的任何其他信息都会被转发给他的新雇主,不过他并没有说那是谁。
事实上,在前一天晚上,Hinton已经决定将他的公司卖给谷歌——他后来承认,这正是他一直以来想要的结果。
百度展现了可以展现的决心,仍错失AI教父Hinton。
有一种说法是Hinton的身体原因,决定了他与中国公司百度之间有巨大障碍。
Hinton的背一直不好,从2005年开始,他甚至不能再坐下,否则随时会有椎间盘脱落的风险。他的背伤,不允许他承受中美两国间的长途飞行——事实上Hinton已经放弃了坐飞机,即便是飞机起落时,他也只能站着。
无论如何,结果是Hinton放弃了获得更高价格的机会,百度也与AI教父擦肩而过。

即便对于这样的结果,百度会有“委屈”,毕竟一直以来,这家科技互联网巨头在中国以技术著称,而且Hinton竞拍中他们也希望通过不断加价证明,对于技术人才的追逐没有上限。
于是,更进一步的观点认为,因为“中国公司”的身份,所以百度“输掉”Hinton争夺战。
我们所知道的阿尔法狗就是Hinton团队的杰作。他的学生Ilya Sutskever是OPENAI的联合创始人,担任首席科学家。
在我充分地了解了AI的前世今生之后,我觉得中国虽然在这个过程中错失了Hinton这样的大师级人物,但是中国并不会错失AI的发展。
AI的发展需要四个要素,算法,算力,传输,训练。
算法是一个数学和工程问题,这方面中国应该是不差的,及时有点差距也能很快赶上,因为基础理论是公开的,论文随时都可以查阅,剩下的工程应用是中国人的强项。
算力呢,中国也不差,通过举国体制搞得东数西算工程,我相信肯定不会差。
传输方面,中国有华为和中兴在5G领域的领先性,应该也不差;
训练,中国更加有优势,其实我觉得对于普通人来说,最可能做的事情就是训练,以后的人工智能训练师将会是一个很大的行业,会产生大量的就业岗位,中国有大量的廉价的高校毕业生。人才优势比较明显。杂乱无章的数据并不能直接用于训练,需要收集,标注,校对,训练。需要大量的人工参与。
任何一项新技术的推广,成本是非常关键的考量因素。据说CHATGPT这种大模型,训练一次的成本在200-1200万美元,运行过程也是巨耗电。据说阿尔法狗下一盘棋的耗电量是840度。
据说预计到2025年全国数据中心的耗电量达到全社会用电量的10%;
华为预计到2030通用计算能力将增长10倍,AI计算能力将增长500倍。用电量是相当可怕的一件事。
未来碳排放目标我觉得大概率是无法达成的,温室效应会进一步加剧,夏天的极端高温天气会越来越多。对电的需求会与日俱增。
当下的人工智能还是不能创新,没有自我意识和情感。但是未来谁知道呢?当参数足够多的时候,谁知道会发生什么情况。将来必然会挣脱人类的控制,甚至和人类争夺资源。人类终于造出了自己的掘墓人和文明的继承人,硅基生命代替碳基生命,延续着人类的文明。
再次想起了三体中叶文洁被捕前的一句话:“这是人类的落日”。
创作不易,喜欢的给打个赏,鼓励一下我吧。
创业项目群,学习操作 18个小项目,添加 微信:luao319 备注:小项目!
如若转载,请注明出处:https://www.fqkj168.cn/4581.html
相关推荐
-
饺子包包是什么牌子,饺子包的品牌
最近,饺子包包受到了不少关注,很多人都想知道饺子包包到底是什么牌子,饺子包的品牌究竟是什么。在这篇文章中,我们将揭秘饺子包包的真正品牌,并探寻饺子包的品牌秘密。 首先,让我们来看看…
-
微信红包封面是永久的吗,拼多多微信红包封面是永久的吗
微信红包封面是永久的吗,拼多多微信红包封面是永久的吗 随着移动支付的普及,红包已经成为人们在节假日和特殊场合常见的礼物方式。微信红包作为中国领先的社交平台之一,自推出以来便深受用户…
-
抖音个人简介怎么写才吸引人,抖音个人简介怎么写吸引粉丝?
抖音作为当下最火爆的短视频平台,拥有庞大的用户群体。如何在众多抖音用户中脱颖而出,成为人们关注的焦点?一个个人简介恰到好处的撰写,可以成为你的吸粉神器! 一、简洁明了 一个个人简介…
-
了解西周劳动人民的生活情况最好查阅,了解西周劳动人民的生活情况最好查阅哪本书
一、西周奴隶制国家的强化(一)周王朝的建立 1.周族的兴起 ①周族原居于今陕西渭水中游以北,传说为帝喾后裔,属姬姓之族,虞夏之际,始祖母姜嫄踩巨人脚印而生弃,定居邰,继承和发展种植…
-
虚拟资源交易平台,虚拟资源交易平台源码
5月23日,据香港证监会官网消息,香港《适用于虚拟资产交易平台营运者的指引》(下称《指引》)将于6月1日生效,该指引订明多项适用于持牌交易平台的标准和规定,其中包括稳妥保管资产、分…
-
cogito人工智能,go做人工智能
作者丨吴思瑾 编辑丨王与桐 * 大语言模型的火爆已经不必多言。在爆发的同时,越来越多其他领域的大模型也开始出现在聚光灯下。 36氪近期接触到一家人工智能模型公司「谜题科技」,聚焦在…
-
乔迁红包封面贺词,乔迁红包封面贺词格式
在中国传统文化中,乔迁之喜是一个非常重要的节日,也是中国人生活中的重要仪式之一。对于亲朋好友们送上一份乔迁红包,不仅象征着对新居的美好祝福,更是传递着对友情和亲情的真挚表达。而一份…
-
人工智能思辨,人工智能思辨性作文素材
随着ChatGPT的爆火,有关人工智能的讨论也热度不断。作为一名具有前沿技术背景、跨学科阅读兴趣的推想小说作者,慕明的首部作品《宛转环》围绕“科技”通过细致深入的线索勾连,编织出了…
-
做点什么副业可以赚钱,手机挣钱的副业
在当今社会,越来越多的人开始意识到仅仅依靠一份工作的收入已经无法满足生活的需求,因此开始寻找一些副业来增加收入。而随着智能手机的普及,手机挣钱的副业也成为了越来越多人的选择。 那么…
-
体育课眼保健操共几节,体育课眼保健操共几节啊视频
来源:【开封广播电视报】 加强学校体育工作 促进学生健康发展 ——开封市示范区学校体育工作经验漫谈 开封市城乡一体化示范区基础教育教研室 王大龙 开封市城乡一体化示范区教育体育局体…